This week I made synonymous changes to the first 100 nucleotides of a sequence when the local base-pairing probability was above 0.1. I repeated this 100 times. Next, I ran each of these 100 sequences (with different synonymous changes) through my program that determines the folding energy and averaged the results. Then, I put these sequences back into the original sequence and run these 100 sequences through my program and averaged the results as well. Finally, I repeated this process for sequences of length 50 and 25 and created a graph (below) to represent the data.
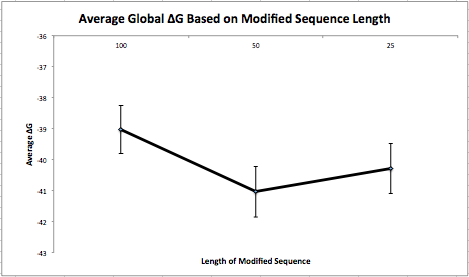
It is important to note that I made the synonymous changes on the same (first) 100/50/25 nucleotides of the sequence and not on random pieces throughout the sequence. I also reverted back to the original piece when making modifications instead of keeping changes that minimized the folding energy. My next experiment will take random pieces throughout the sequence and will put the modified piece back if the changes are advantageous.
This experiment took a great amount of time and effort. I had to make synonymous changes by hand and run my program more than 400 times. To minimize both the workload and time, another research student and are working on developing a program that can generate synonymous changes based on a local base-pairing probability specified by the user, given a Rfold output file.
This experiment took a great amount of time and effort. I had to make synonymous changes by hand and run my program more than 400 times. To minimize both the workload and time, another research student and are working on developing a program that can generate synonymous changes based on a local base-pairing probability specified by the user, given a Rfold output file.
 RSS Feed
RSS Feed
